research
> preface
During my undergraduate degree, I did research on cattle grazing litigation under Dr. Jared Talley and Dr. Ryan Tarver. Grazing is important for Idahoans, with historical, cultural, ecological, and economic dimensions. Grazing is a social issue. I was on a team where most people were in the social sciences. I was not. Working with people from outside your field is very rewarding.
> ready, set, wait
The project began with a lengthy and protracted FOIA request process to get our sources for the research. Dr. Talley and Dr. Tarver handled this process. We had no idea what was going to come out of the FOIA, or when it would be delivered. I used the time to figure out what my steakholders wanted me to build, search for outside data, and research environmental law.
When we finally got our data, we had over 8,000 of pages of PDF documents. These included, inter alia, final verdicts on grazing disputes between ranchers and the Bureau of Land Management. These "final verdicts", henceforth, Final Decisions, provided us samples of grazing litigation.
The population has these qualities:
- ~100 Final Decisions.
- ~40 pages on average.
- Not all documents were exported from a document editor.
- Scanned documents ➞ No Ctrl + F
- 10 years of documents
- Many different counties
> square peg, square hole
Now the real work could begin. How do we turn raw data into useful insights? We had no idea, so Dr. Tarver and I started skimming documents. As we read, we found some features that every document shared. These features helped us understand the shape of the documents; square pegs. I began encoding the features of these documents in json, and developing a schema. The schema was the square hole.
As I encoded more documents, I realized that I made a terrible mistake. I was encoding the documents chronologically. My schema broke when the Bureau of Land Management changed formats, and it really hurt. I continued working, with my new approach of randomly selecting a document. I found this pipeline delightful
$ ls -1 | shuf | head -n 1
shell is so underrated... The random selection technique worked well, and the schema evolved quickly. This was the first (and only) time I had to rewrite it. I lost a lot of time and work, but I gained a valuable lesson. If you don't understand the data set, don't bias your sampling. The square hole does fit square pegs, but not all pegs are square.
> eating elephants
Once I was reasonably confident my schema wouldn't break again, I started encoding documents. I was really dreading this part. It was going to be exceptionally tedious, and I could not make any mistakes. These sorts of tasks can be difficult to finish. They can also be difficult to start. My morale was suffering after losing most of my previous work to the schema rewrite.
When I brought this up to Dr. Talley, he asked me, "How do you eat an elephant?" One bite at a time of course. As cliché as this sounds, it really did motivate me. I wanted to be done with the elephant, so I started taking bites. Imagine an epic montage of me doing data entry. Sounds badass, right? Eventually I had encoded enough data to be happy, and I could move on to something more fun.
> eating dessert
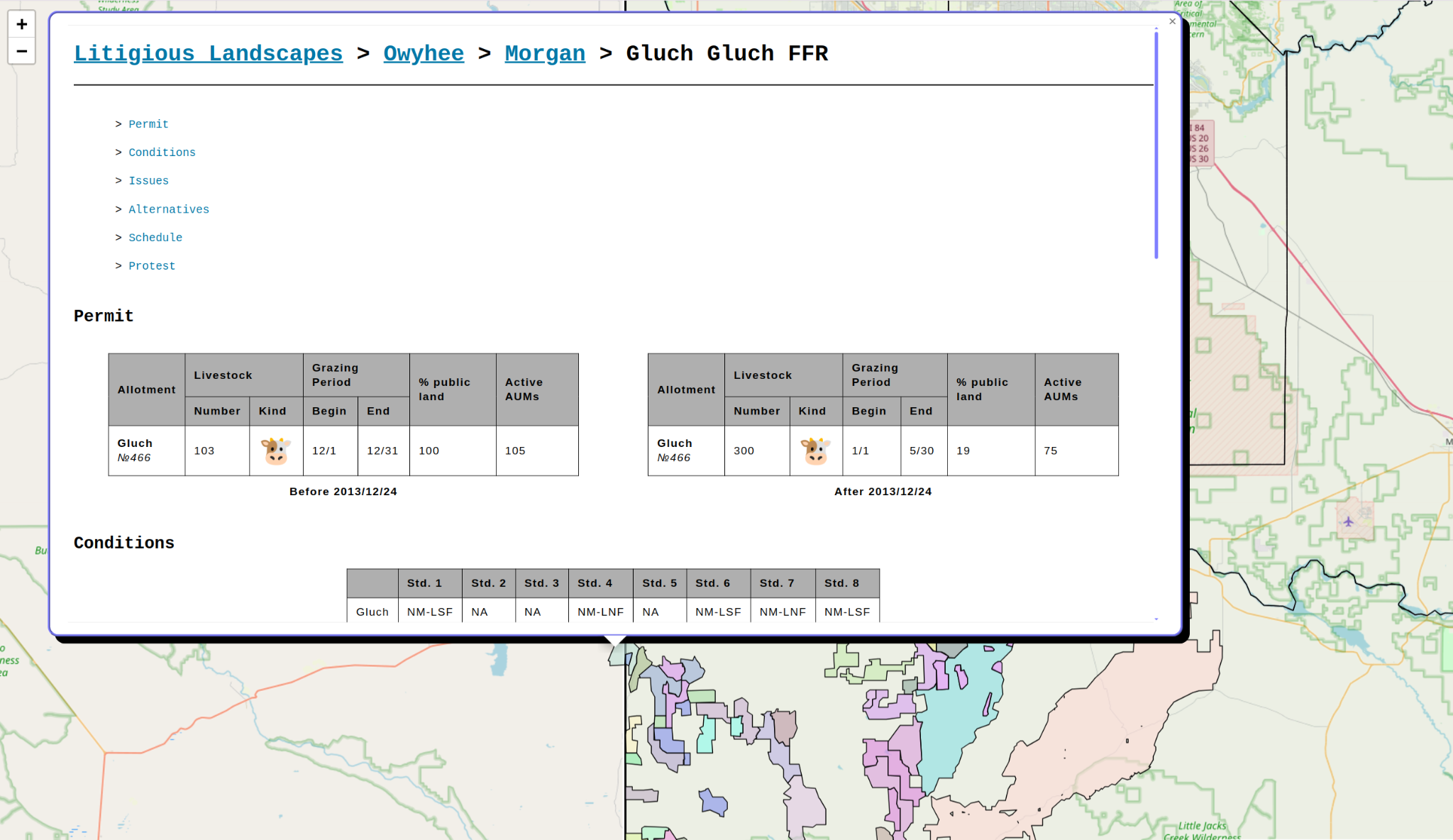
This was the fun part. I built a geospatial single page web application to present the encoded documents in a useful manner. Back when we were waiting on the FOIA, I found a geojson file with the land parcels that these lawsuits were being filed over. The geojson included fields for the Allotment Number, which let me map my encoded data to land parcels.
After writing a quick & dirty http server in Go, I started working on the front end. I used LeafletJS. I hadn't ever used a library like this, so I didn't want to overthink it. It was really easy, and in 4 hours I had a map with colored land parcels. Clicking on a land parcel would reveal a nicely formatted overview of the lawsuit.
> figures